
こんにちは。株式会社エル・ティー・エスの渡辺翔太です。
前回は機械学習について学習し、その中でもよく利用されるロジスティック回帰モデルについて解説しました。今回も機械学習のひとつであるクラスター分析について解説していきたいと思います。
その前に、まずは機械学習の話題で良く出てくる「教師あり学習」「教師なし学習」という言葉について説明したいと思います。
教師あり学習と教師なし学習
機械学習の中には、教師あり学習と教師なし学習という2種類の学習があります。その違いは、教師データが必要かどうかです。教師データとは正解データとも呼ばれ、ある原因データに対する結果に相当するデータとなります。図で見ると分かりやすいでしょう。
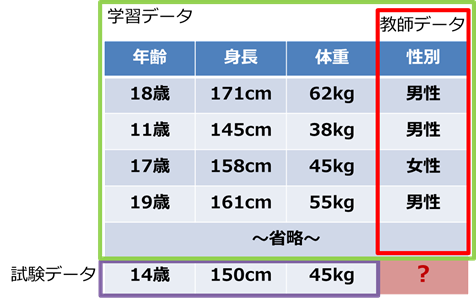
図では年齢・身長・体重・性別のデータがあります。また、試験データとしてある年齢・身長・体重のデータがあります。この試験データの性別が男性か女性かに分類したいとしましょう。
この時、過去のデータに性別のデータがないと、いくら頑張ってもコンピュータは試験データから性別を分類することができません。過去の年齢・身長・体重というデータから性別データを学習して初めて、分類することができます。
このように、分類や予測をしたいデータが教師データに該当します。身長・体重・性別から年齢を予測したい場合は、年齢データが教師データになります。何を予測したいのかによって教師データは変わり、予測したいものがデータにない場合は、教師あり学習をすることはできません。
一方、教師なし学習とは教師データを必要としない機械学習です。予測の場合には教師データが必要でしたので、教師なし学習は予測には使えません。ではどのような場合に用いるかというと、似ているデータ同士をまとめたいときに用います。
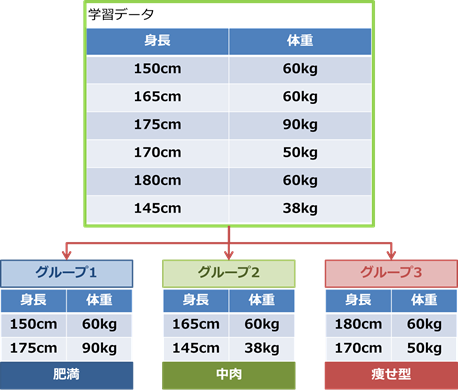
教師なし学習では、身長と体重のデータから似た傾向にあるデータ同士を一つのグループにまとめ、似ていないものとグループを分けることができます。ただし、どういった観点で似ているのかは人間がデータを見て判断する必要があります。
図のグループでは肥満、中肉、痩せ型というグループに分かれていますが、コンピュータにこのように分類しろと教えたわけではなく、コンピュータが自動的にグループ化したものを人間が見てグループに名前を付けたのです。
結果によっては、人間が見てもどこが似ているのかが分からない、どのように名前を付けたらよいのか分からない、などのグループ分けになることも多いです。その場合は、その結果を用いず別のロジックを使ってビジネスに活用しやすい結果が得られるまで試行錯誤する必要があります。
まとめると、教師あり学習はデータを分類したりデータから予測したい場合に使われる教師データが必要な学習であり、教師なし学習は似たもの同士をグループに分けたい場合に使われる教師データが必要ない学習となります。
クラスター分析とは
教師なし学習のほとんどはクラスター分析に該当します。クラスター分析とは、クラスタリングとも呼ばれ、データから似ているもの同士をひとつのグループに振り分け、逆に似ていないデータは異なるグループに振り分けられるようにしていくつかのグループ(=クラスター)に分ける手法です。
ここで注意すべきなのが、もともとすでにグループの特性がありその特性に近いデータが振り分けられるわけではないということです。たとえば画像認識において犬の画像と猫の画像がたくさんあるとしたとき、あらかじめ各画像が犬か猫を分類しておき、その分類に基づいて新しい画像が犬の画像か猫の画像かを分類するのはクラスタリングではありません。
クラスタリングはたくさんの犬と猫の画像から似ているもの同士をグループに分ける手法で、結果として犬の画像が集まったクラスターと猫の画像が集まったクラスターに分かれることになります。
そして、”似ている”の基準が適切でないと意図しないクラスターになってしまいます。犬と猫に分けたいのに、室内の画像が集まるクラスターと屋外の画像が集まるクラスターに分かれたり、毛色が明るい色か暗い色かで分かれたりしてしまいます。
以上のことから、クラスタリングは分類(クラシフィケーション)とは明確に異なるということが分かります。クラスタリングが要素(データ)から構成を作りだすのに対し、分類はすでにある構成に要素を当てはめることを意味します。
ところで、前回の機械学習とは何かを解説した部分で、「機械学習とはデータがもつ構造的な特性を学習することで、構造(モデル)を仮定しデータに最も当てはまるように特性値(パラメータ)を計算すること」と書きました。
クラスター分析をこの考えに則って記述すると、仮定する構造(モデル)は「似ているデータ同士をN個のクラスターに分けることができる」であり、計算する特性値(パラメータ)は「各データがどのクラスターに属すかを表すクラスター番号」となります。なお、多くの場合クラスターの数は人が決めなければなりません。(※)
※クラスタリングの結果から適切なクラスター数を決める方法と、あらかじめクラスター数を決めてクラスター分析を行なう手法があります。クラスター数が自動で決まる手法もありますが、あまり一般的ではありません。
データが似ているとは
ここまで、クラスタリングはデータが似ているもの同士をクラスターに分ける手法と説明してきました。そして、クラスター分析で最も重要なのが、データが何をもって似ているか表す基準です。
データの種類(次元)が1つしかなく、かつ数値だったとしましょう。5つのデータ1、1.1、3、4、10があるとします。このデータを3つの似ているグループに分けるとした場合、多くの人が{1、1.1}、{3、4}、{10}と分けるのではないでしょうか。この分類の基準はデータ間の差が小さいものほど似ているという基準です。クラスター分析でも同様に、データ間の差の大小を基準にします。そして、データ間の差のことを”距離”と呼びます。
2種類(2次元)の数値データの場合、(1,3)と(2,5)の距離は
![]()
のように計算すると高校時代に習ったと思います。この距離のことをユークリッド距離と呼びます。クラスター分析では、このユークリッド距離以外の距離も使用します。他の距離を用いると(1,3)と(2,5)の距離は√5ではなく3になったり0.998になったりします。
なぜいろいろな距離があるかというと、データには単位があるということと、数値以外も取りうることが関係しています。(1,3)と(2,5)のデータが、もし単位付きで考えると(1mg,3km) と(2mg,5km)だったとします。1mgと2mgの差は感覚的には微々たる差です。一方3kmと5kmは結構大きな差に感じます。これを同等に扱うことがあまり良くないことはなんとなく感じられるではないでしょうか。また、(19歳,男性) と(23歳,女性)という2つのデータはもはやユークリッド距離を求めることはできません。
以上のことから、クラスター分析ではデータに合わせて適切な距離を選択し、距離が小さいデータを似ていると判断することが分かりました。
ここまでで少し長くなってしまったので、次回はクラスター分析の種類やどのような距離があるのか、そしてそれらをRで実行するにはどうすればよいのか解説していきたいと思います。
アサインナビでは、データサイエンスに関するセミナーを随時開催しております。
過去には、データサイエンティストの知識を習得するための実践塾や、特別講師を招いてのセミナーなどを開催しております。
過去の様子はこちらからご確認いただけます。
▼データサイエンティスト実践塾▼
第1回データサイエンティスト実践塾を修了しました!
▼データサイエンスの現状と未来▼
シリコンバレーに学ぶ、日本のデータサイエンスの現状と未来 ~これからのデータドリブンな時代に本当に必要なこと~を開催しました





