
こんにちは。株式会社エル・ティー・エスの渡辺翔太です。
前回「データサイエンティストのお仕事とは?R導入編」はRとR Studioのインストールを行いました。
今回から実際にR Studioを用いてデータを分析していきたいと思います。

Rの基本的なプログラミングを学ぶ
それでは早速R Studioを開いてみましょう。
エディタ画面に前回の指示文(コード)が残っていましたね。このまま続きを書いても良いですし、[Ctrl+Shift+N]で新しいエディタ画面のタブを作成することもできます。
①変数と代入
さて、他のプログラミング言語と同様に、Rにおいても変数という重要な概念があります。変数とは、データに固有の名前(変数名)を与えたものです。そして、変数名とデータを紐付けることを代入と言います。
例えば、“2”という数値のデータをxという名前の変数に代入するとします。
するとxは2という数値として扱うことができます。
1つの数値以外にも、数列(複数の数値の並び)や文字の列、行列(縦×横に並んだ数値)など、いろいろなものを変数に代入することができます。
少し難しいお話になりましたが、要するにデータに名前を付け、その名前でデータの計算や処理を行うということです。
実際にxという変数に2という数値データを代入してみましょう。
Rでは <- という記号が代入を指示するコードになります。
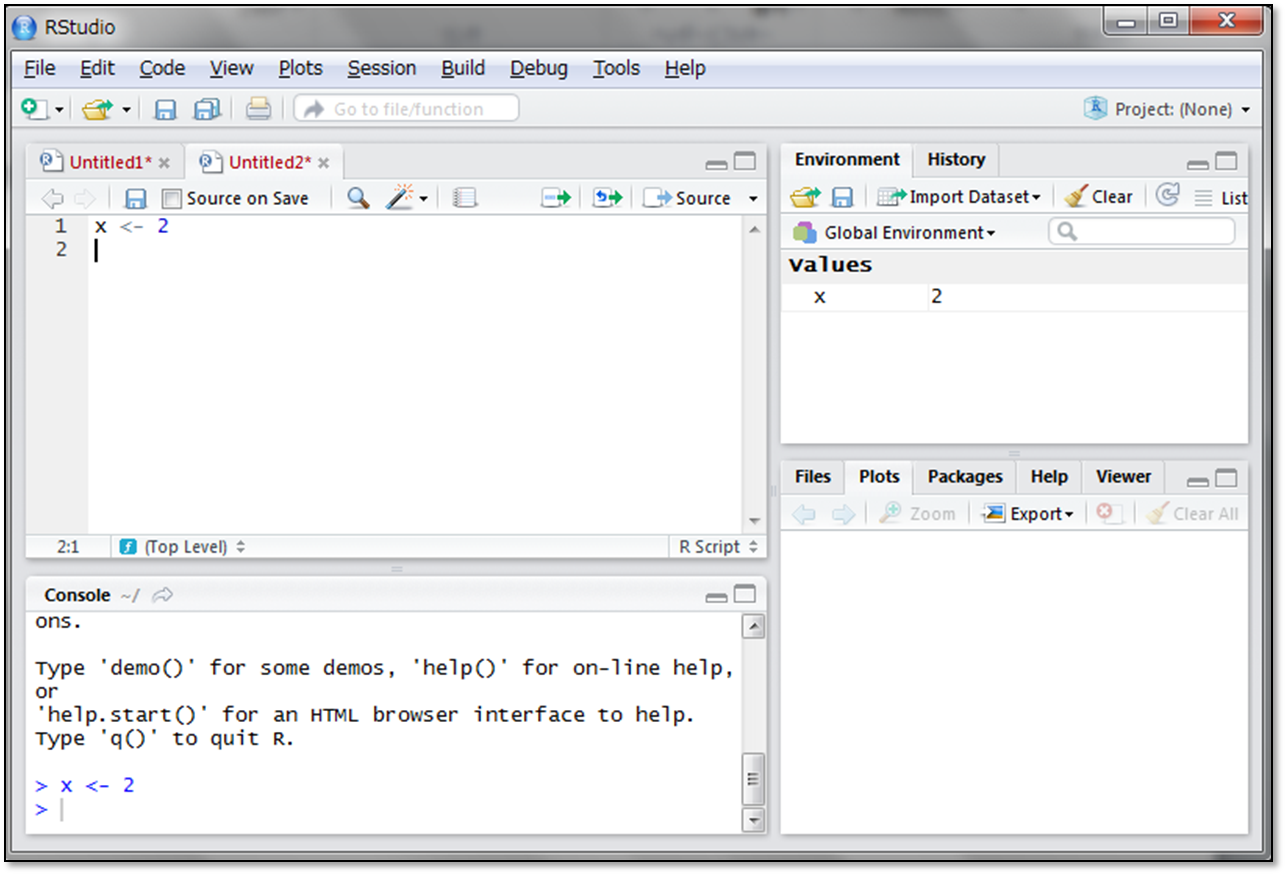
「x <- 2」と書いてCtrl+Enterで実行するとxという変数に2が代入されます。
xの中身を見たい場合は、単純に変数名「x」と記述して実行します。
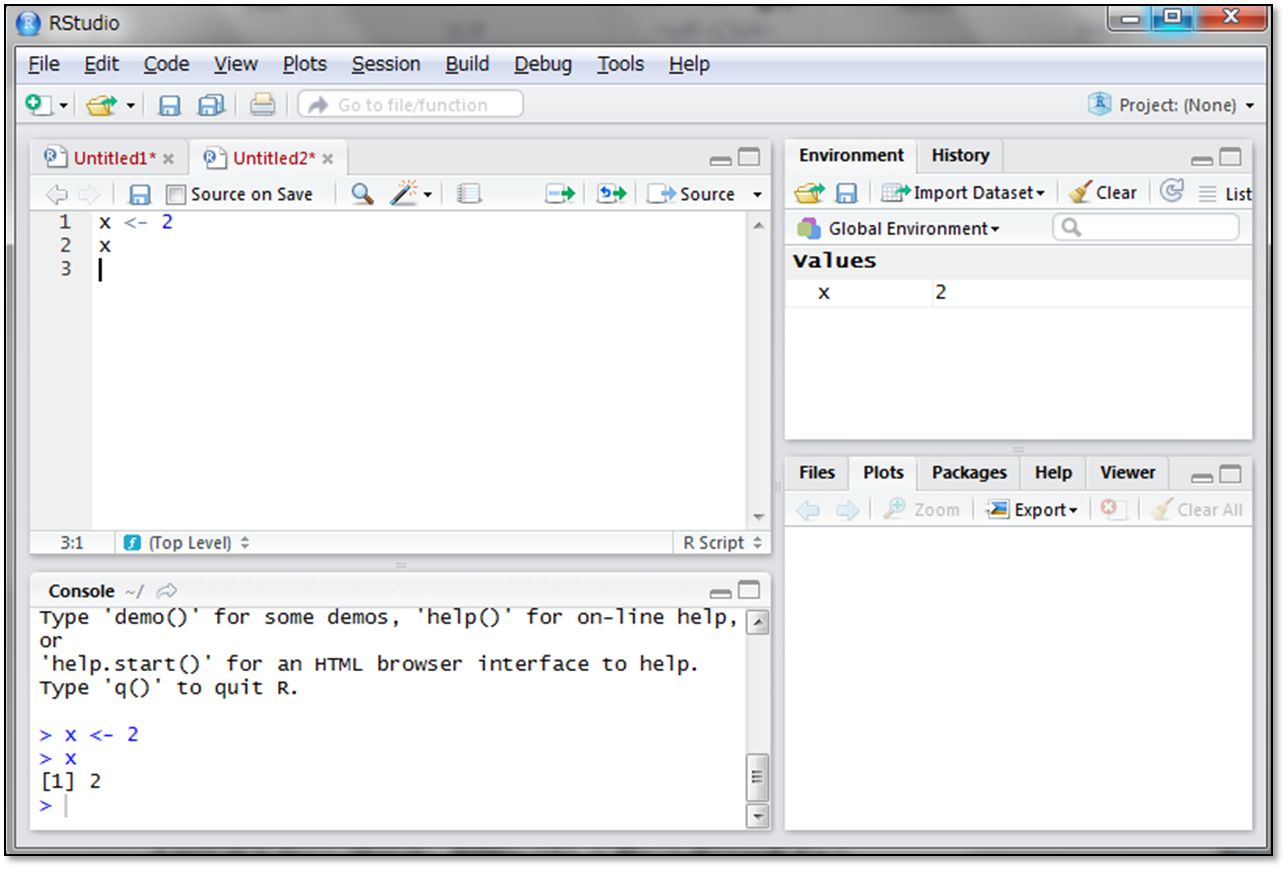
xの中身が2であることが分かりました。ここで、別のデータをxに代入すると、それまでの2というデータが別のデータに上書きされます。一度上書きされるとそれまでのデータは消えてしまいますので、なるべく変数を作成するときには別の変数名を用いることをお勧めします。
続いてsuretsuという変数名の変数に、複数の数値を代入してみます。
「suretsu <- c(1,2,1,4,6,5)」と書いて実行してみましょう。
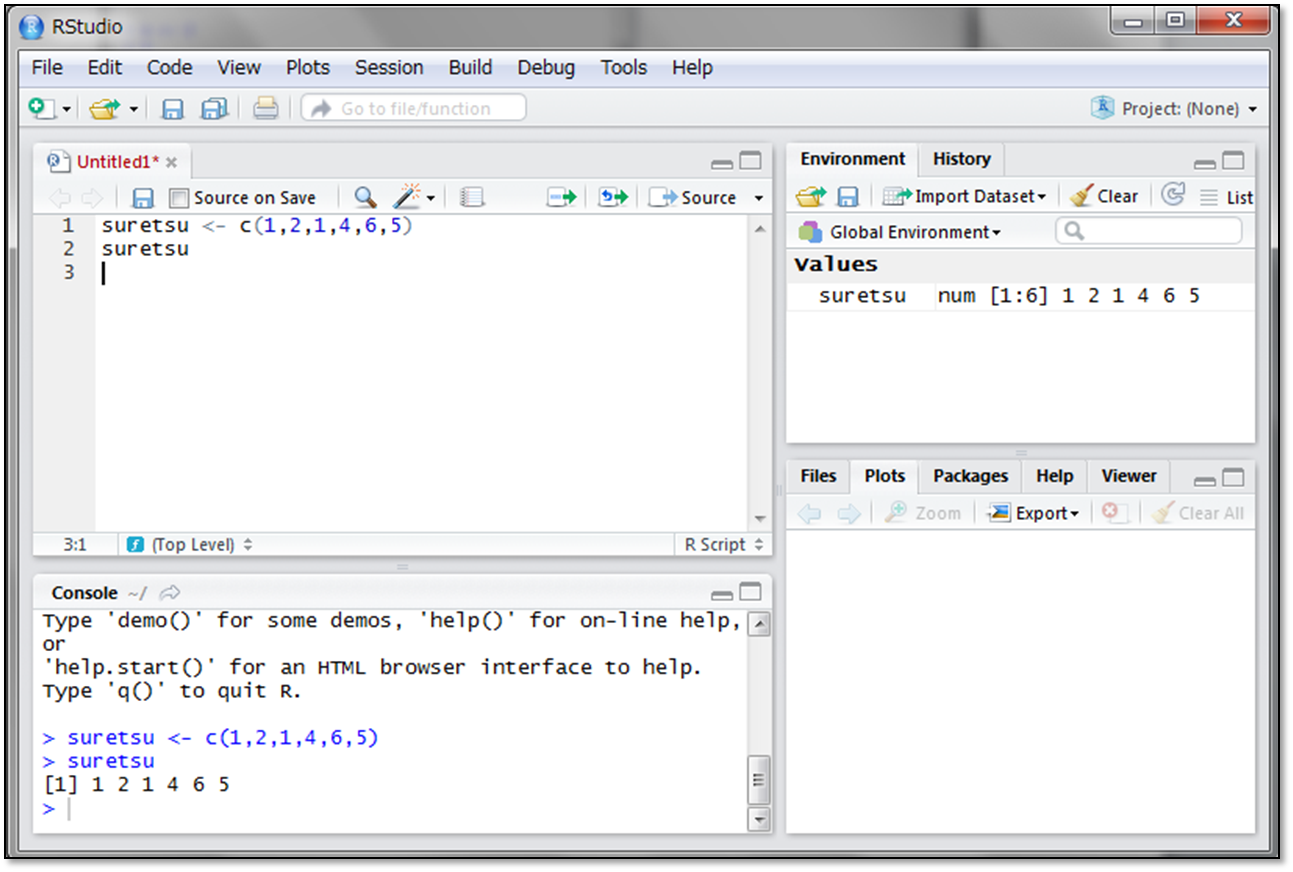
変数suretsuに、6つの数値からなる数列データを代入することができました。このように複数のデータが並んだ変数構造のことを、Rではベクトルと呼びます。また、ベクトルの各データのことを要素といいます。
c()というのは、ベクトルを作成する指示文で、c()の中にデータをカンマ(,)で区切って入れることで数列を作ることができます。
ところで、変数名を付ける際には次のルールに気を付ける必要があります。
・数字を先頭にすることはできない
・英数字、日本語のどちらも自由に組み合わせられる
・半角記号はアンダーバー(_)とピリオド(.)のみ使用できる
②データの型
Rのデータには、次のように型というものが決まっています。
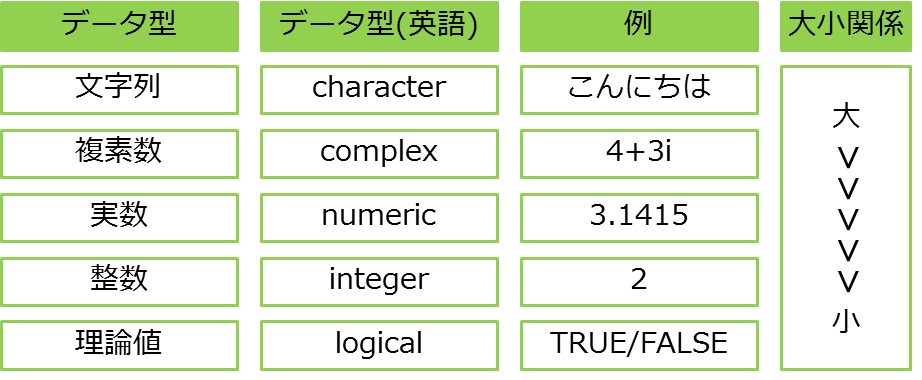
理論値とは、真か偽の二者択一を表すデータであり、Rでは真のことをTRUE、偽のことをFALSEと表記します。
ベクトルの要素は、すべて同じデータ型である必要があります。そのため、型が異なる要素をc()でベクトルにする場合、データの型が統一されます。その際、統一される型は、要素の型の中で大小関係の最も大きな型となります。
次の例を見てみましょう。
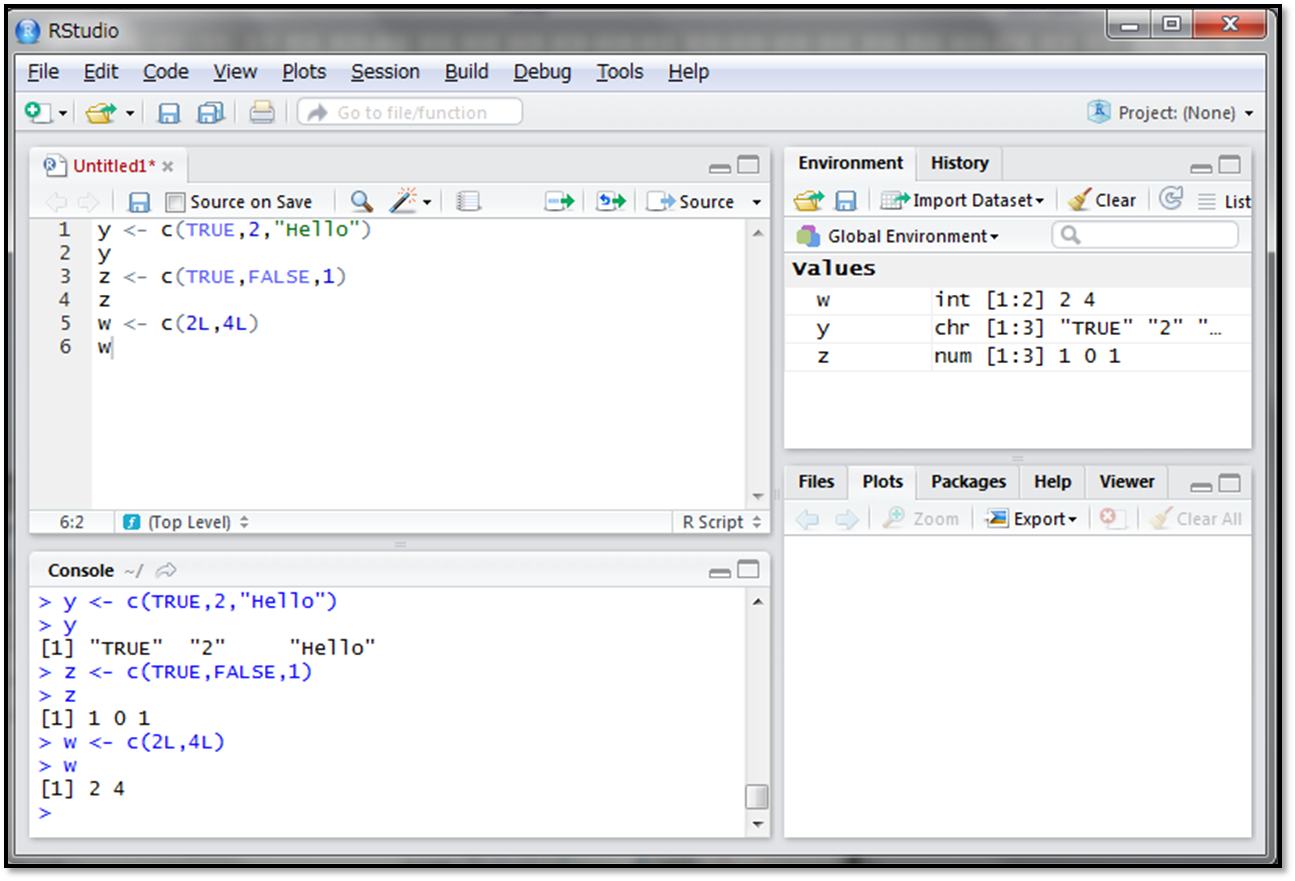
1行目では変数yに、理論値のTRUE、実数の2、文字列のHelloをベクトルとして代入しています。2行目で実際にyの要素を見てみると、ダブルクォーテーション(””)でくくられた要素が並んでいます。代入したデータの型のうち、最も大きい文字列型に統一されています。
3行目では変数zに、理論値のTRUE、理論値のFALSE、実数の1を代入しています。4行目で実際にzの要素を見てみると、1、0、1というデータが並んでいます。これは実数型においてTRUEは1、FALSEは0として認識されていることを意味します。
5行目では整数の後ろに“L”を書いています。通常、整数をそのまま記述すると実数の型として認識されます。明示的に整数型を指定する際には、このように”L”を書くことで整数型として扱うことができます。
③条件
Rの機能のひとつに、ベクトルの要素がある条件を満たすかどうかを理論値で返すものがあります。具体例を見てみましょう。
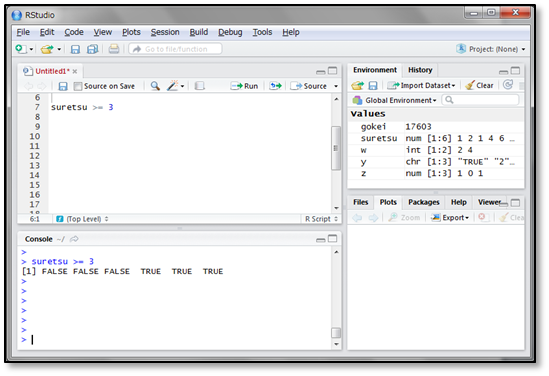
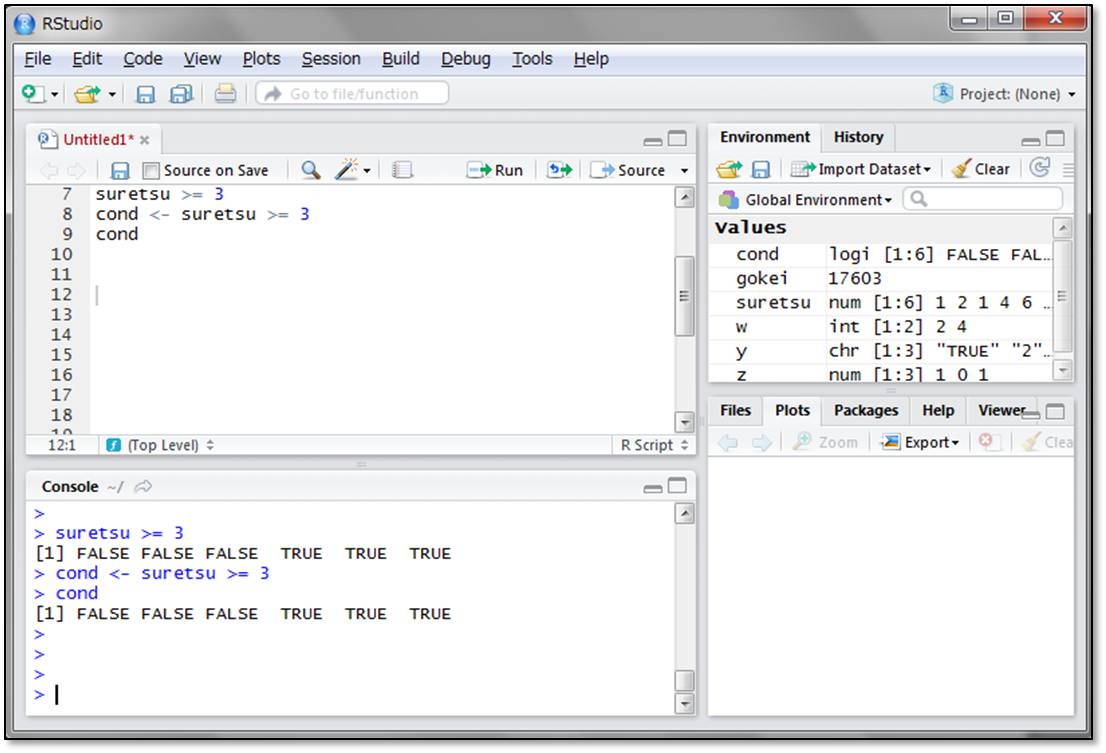
先ほど作成したsuretsuというベクトルの要素のうち、3以上の要素かどうかを判定し、TRUEかFALSEで返しています。また、結果を代入することができ、代入先の変数は理論値を要素とするベクトルになります。
条件を指定するコードは次のようなものがあります。

④関数
c()のように、○○()という指示文のことを関数といい、()の中にデータや変数を入力で、関数に特有の処理を実行することができます。()の中に入力するデータや変数のことを引数といいます。Rにはたくさんの関数がデフォルトで用意されています。例として合計を求めるsum()関数を紹介します。
ここに、5人のある商店での購入金額データがあります。

この5人の購入金額の合計をsum()関数で求めてみましょう。sum()関数は引数に足される数を入力します。複数の引数を入力する場合はカンマで区切ります。
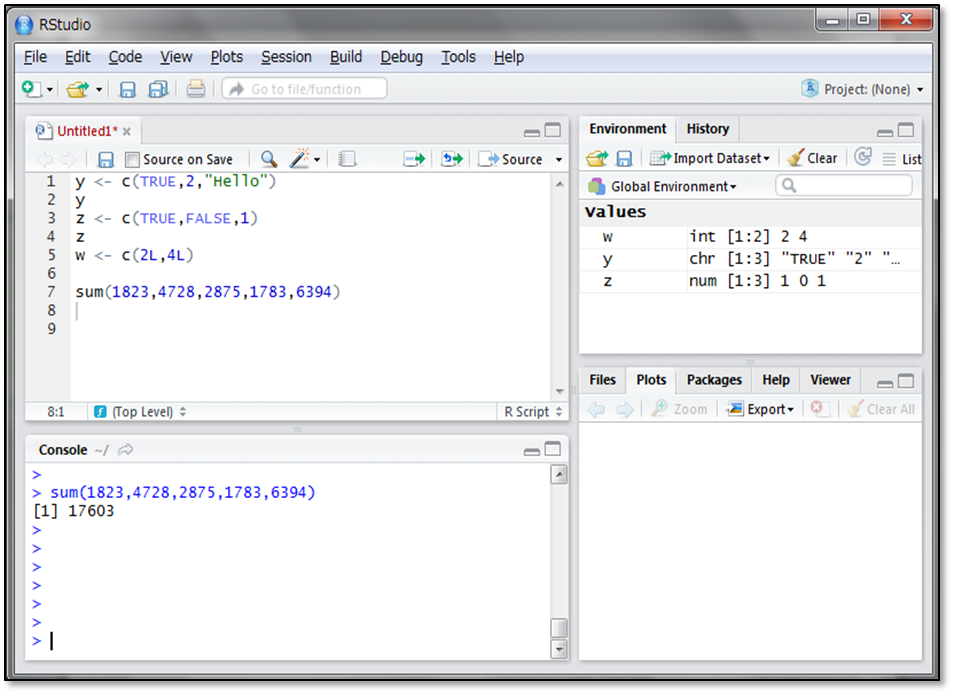
合計金額が17,603円であることが分かりました。また、計算結果を代入することもできます。
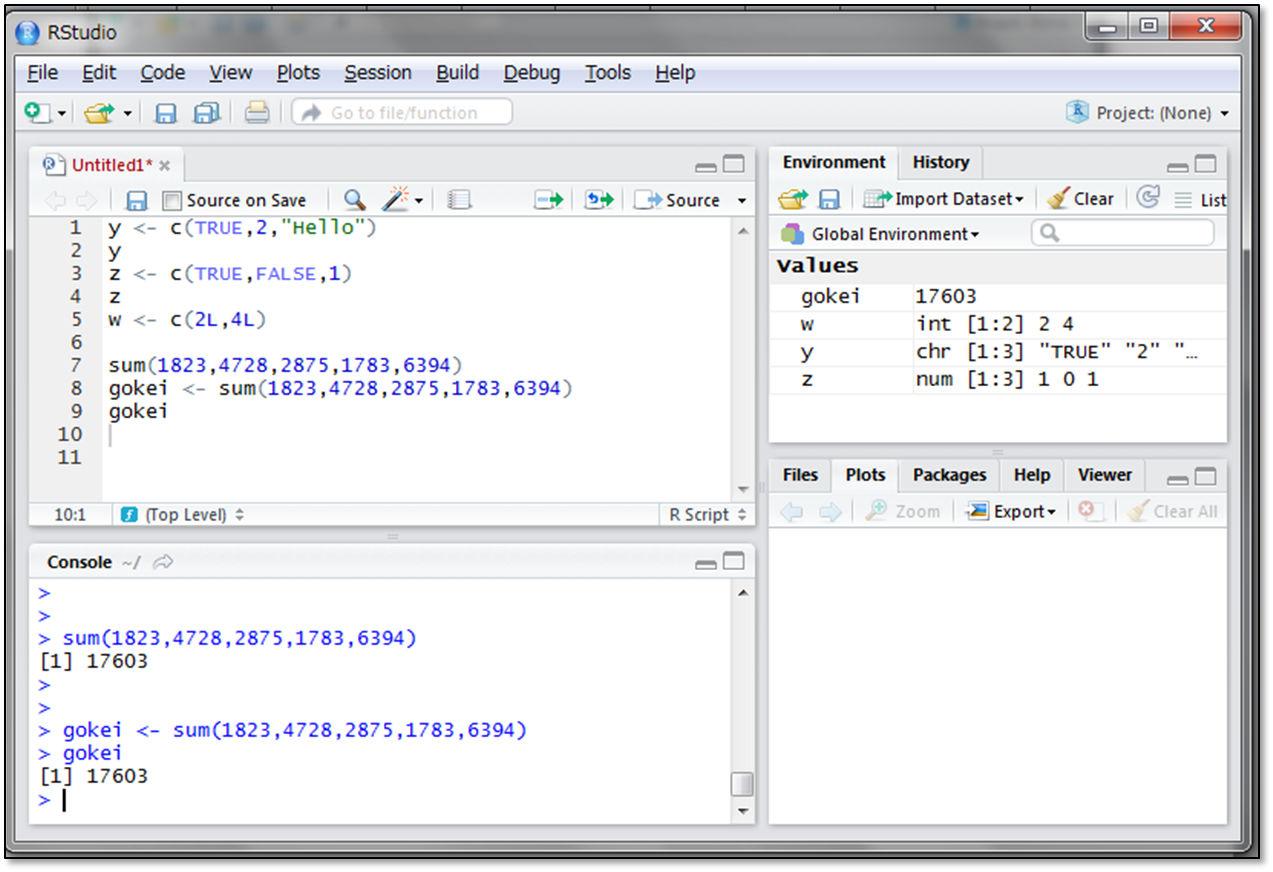
代入した結果を、別の処理を行う関数の引数に指定するができます。Rは統計処理を行う関数が豊富に用意されています。分析に必要な処理を行う関数を、インターネットや書籍などで調べながら用いましょう。
また、今後もこのコラムではたくさんの関数が出てきます。ひとつずつ、どのような処理を行う関数なのかを確認しながら読み進めてくださいね。
Rで表データを扱う
①データフレーム
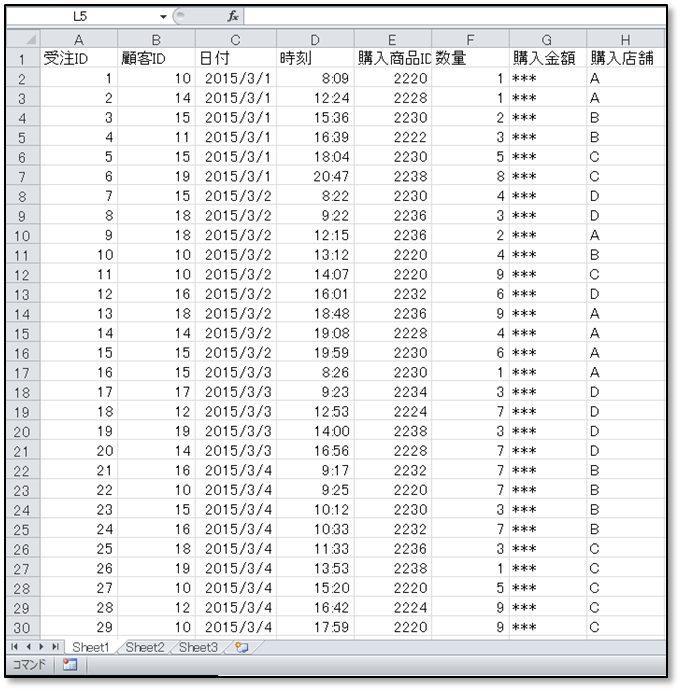
IT技術が進歩し、様々なビジネスデータが整理された状態でシステムに格納されるようになりました。整理された状態とは、下図のように各列に同じ形式の値が格納された表データを指します。
Rでも、このような表形式のデータ構造が用意されています。このデータ構造のことをデータフレームといいます。Rにデフォルトで用意されているデータフレーム構造のデータの一つに、「iris」というものがあります。実際に見てみましょう。
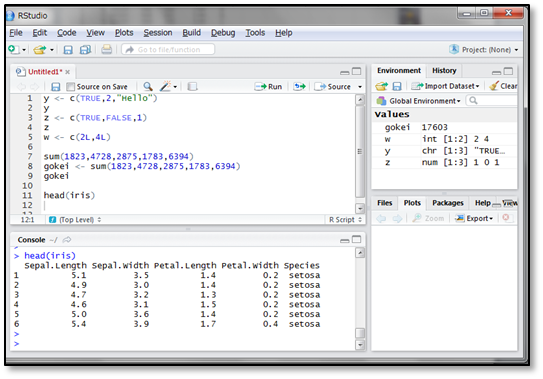
※ここではhead()関数を用いて、6行分のデータのみ示しています。
このデータは、アヤメという植物150個体について”がく”の長さと幅、花びらの長さと幅、個体の種名を調査したものです。各列の表頭に”Sepal.Length”、”Sepal.Width”、”Petal.length”、”Petal.Width”、”Species”という列名が付いており、各行が1個体のデータを示しています。
データフレームの実体は、各列をひとつのベクトルとしたベクトルの集合体になります。データフレームから、一部のデータを抽出したい場合の処理をまとめました。
基本のコード
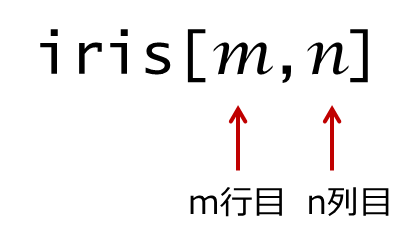
これで、m行n列目のデータを抽出することができます。
この形を応用して複数のデータを抽出します。
複数のデータ抽出コード①
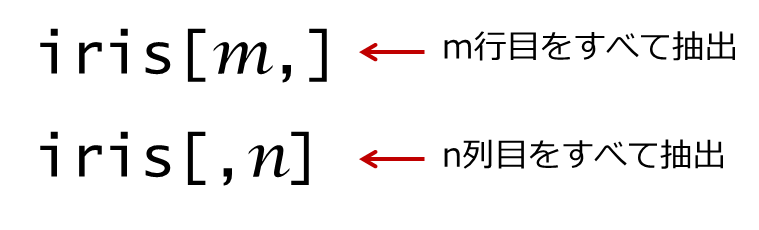
各行または各列のすべてのデータを抽出する場合は、空欄にします。
複数のデータ抽出コード②
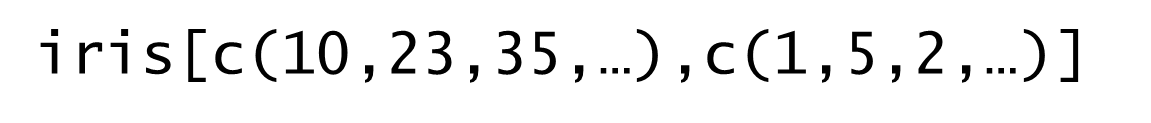
複数行・複数列のデータを指定する場合は、ベクトルを用いて指定します。
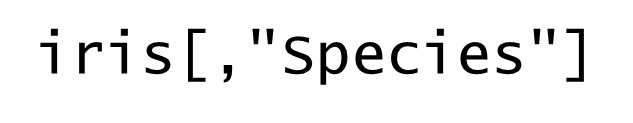
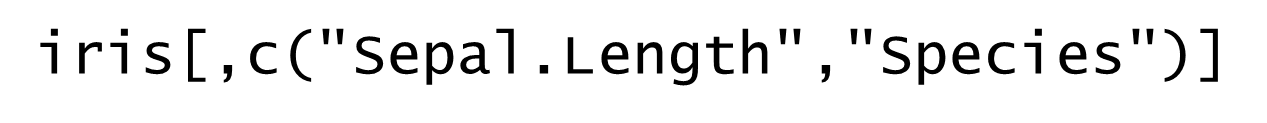
列名が分かっている場合は、列名をダブルクォーテーションで括って指定することで抽出できます。複数の列名をベクトルで指定することもできます。
複数のデータ抽出コード③
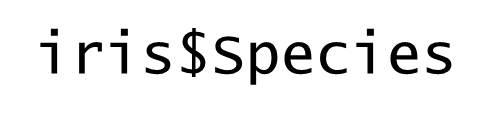
列名が分かっていて、1列だけ抽出したい場合には、上図のようにデータ名と列名をドルマーク($)でつなぐことでも抽出できます。このとき、ダブルクォーテーションは不要です。
複数のデータ抽出コード④

理論値を用いても抽出することができます。この場合、1、3、5列目だけが抽出されます。これを応用して、ある条件を満たすデータだけ抽出することができます。
たとえば、Sapal.Lengthが6.0以上のものを抽出してみましょう。まず、Sapal.Lengthが6.0以上という条件を理論値ベクトルで見てみます。
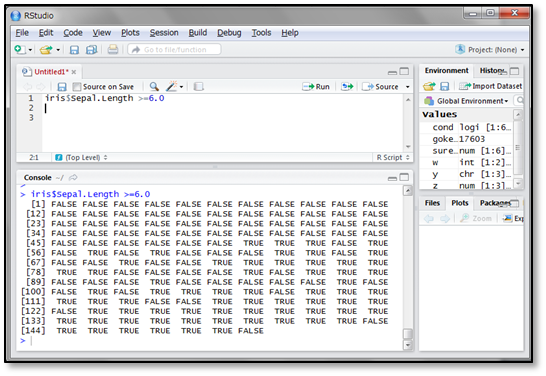
150個体のうち、Sepal.Lengthが6.0以上のものはTRUE、それ以外のものはFALSEとなっています。この結果を用いて、Sepal.Lengthが6.0以上の個体の全データを見てみましょう。
「iris$Sepal.Length >= 6.0」というコードそのものが理論値ベクトルを出力するので、これをそのままiris[○○,]の○○の部分に記述します。
![「iris$Sepal.Length >= 6.0」というコードそのものが理論値ベクトルを出力するので、これをそのままiris[○○,]の○○の部分に記述します。” width=”548″ height=”360″ class=”aligncenter size-full wp-image-2543″><br />
以上が主なデータフレームからのデータ抽出法でした。</p>
<p><u>②表データの取り込み</u></p>
<p>実際のデータ分析では、エクセルなどで保存している表データをRに読み込ませる必要があります。しかし、デフォルト環境ではエクセル形式のファイルをRに読み込ませることはできません。Rに読み込ませるには、エクセル形式のファイルをCSV形式に変換する必要があります。</p>
<p>CSV形式で保存するには、「名前を付けて保存」画面の「ファイルの種類」から「CSV(カンマ区切り)(*.csv)」を選択して保存してください(メッセージが出る場合は、「はい」を選択してください)。また、Rで読み込む際に、ファイルの保存先が必要のため、保存先をきちんと把握しておいてください(慣れるまではデスクトップに保存するようにすると良いでしょう)。<br />
<img loading=](https://assign-navi.jp/magazine/wp-content/uploads/2016/08/image24.png)
表データをCSV形式で保存できれば、Rに読み込ませる準備が整いました。
(i)まず、CSVファイル存在するファイルをRで指定します。
setwd()関数という関数を使います。
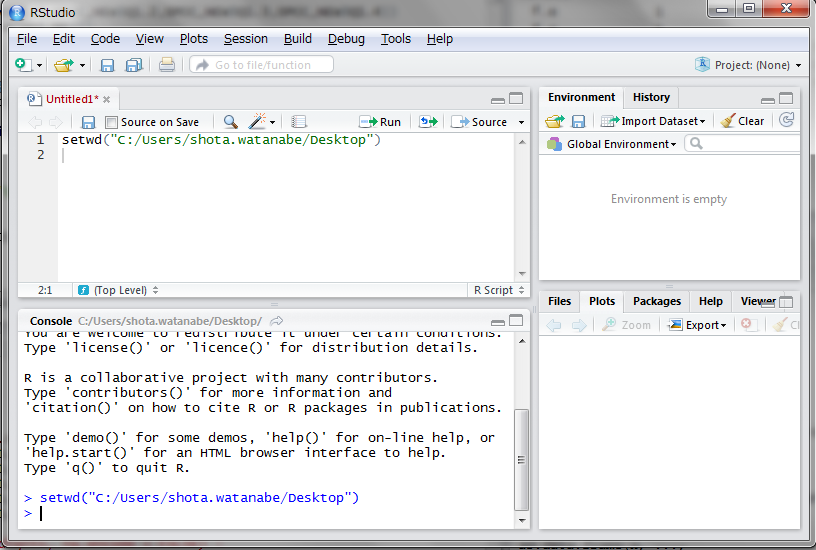
setwd()の引数にダブルクォーテーションでくくったフォルダのパス名を指定し、実行します。実行結果の表示は特にありませんが、これでフォルダを指定できました。
(ii)次に、CSVファイルを読み込みます。
read.csv()関数という関数を使い、引数にファイル名を指定します。
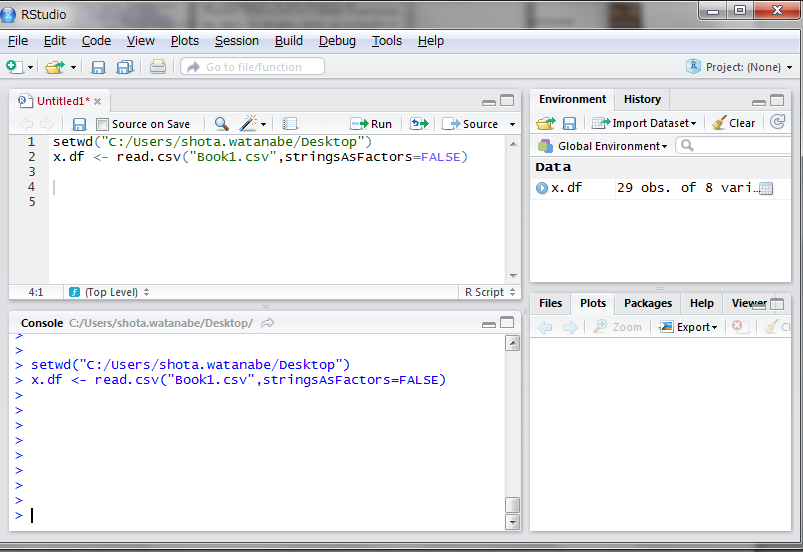
ここではx.dfという変数にCSVファイルを代入しています。変数に代入しないとその後の処理を行うことができません。また、「stringsAsfactors=FALSE」というのは関数の処理に関するオプションの設定で、「因子型にしない」という指定を与えています。この指定を与えないと、文字列データが自動で因子型に変換されます。因子型とはデータ型のひとつで、文字列データに内部的に数値を与え、計算ができるようにしたものです。しかし、因子型は少し扱いにくいので、ここでは「因子型にしない」と明示的に指定しています。
以上で表データを読み込み、x.dfという変数に代入することができました。
次回はいよいよ統計的な分析にテーマを進めてまいりたいと思います!
アサインナビでは、データサイエンスに関するセミナーを随時開催しております。
過去には、データサイエンティストの知識を習得するための実践塾や、特別講師を招いてのセミナーなどを開催しております。
過去の様子はこちらからご確認いただけます。
▼データサイエンティスト実践塾▼
第1回データサイエンティスト実践塾を修了しました!
▼データサイエンスの現状と未来▼
シリコンバレーに学ぶ、日本のデータサイエンスの現状と未来 ~これからのデータドリブンな時代に本当に必要なこと~を開催しました





