
こんにちは。株式会社エル・ティー・エスの渡辺翔太です。
仮説検定編(1)に引き続き、今回も仮説検定について進めたいと思います。
前回は仮説検定の概要をお伝えしました。今回のコラムでは、実際にRを用いて仮説検定を行いたいと思います。
t検定のやり方
前回のおさらい
t検定は一般的に2群の平均に差があるかどうかを検定するものです。「今月と前年同月の平均客単価の差」「今月と前年1年間の平均客単価の差」「キャンペーン施策前後の顧客の購入意欲の変化」などを検定することができます。
早速、この3つの検定を実際に行なってみましょう。
データの準備
画像のようにコマンドを実行し、データを準備します。
今回はCSV取り込みを行いませんので、直接ダミーデータを作成しています。
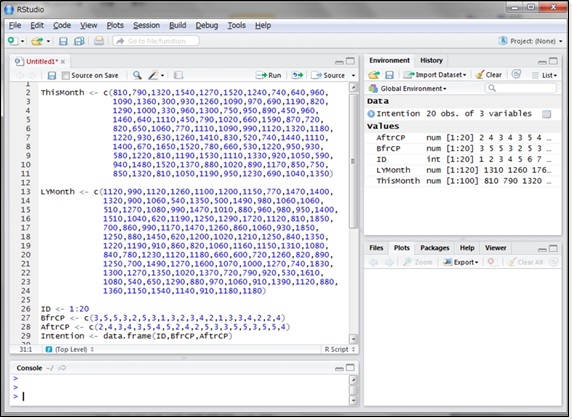
変数の説明
- ThisMonth:今月の購買金額(100件), データ型=ベクトル
- LYMonth:前年同月の購買金額(120件) , データ型=ベクトル
- Intention:顧客の購入意欲, データ型=データフレーム
- Intention$ID:顧客ID
- Intention$BfrCP:キャンペーン前の顧客の購入意欲(5段階評価)
- Intention$AftrCP:キャンペーン後の顧客の購入意欲(5段階評価)
【コピー&ペースト用データ】
ThisMonth <- c(810,790,1320,1540,1270,1520,1240,740,640,960,
1090,1360,300,930,1260,1090,970,690,1190,820,
1290,1000,330,960,1300,750,950,890,450,960,
1460,640,1110,450,790,1020,660,1590,870,720,
820,650,1060,770,1110,1090,990,1120,1320,1180,
1220,930,630,1260,1410,830,520,740,1440,1110,
1400,670,1650,1520,780,660,530,1220,950,930,
580,1220,810,1190,1530,1110,1330,920,1050,590,
940,1480,1520,1370,880,1020,890,1170,850,750,
850,1320,810,1050,1190,950,1230,690,1040,1350)
LYMonth <- c(1120,990,1120,1260,1100,1200,1150,770,1470,1400,
1320,900,1060,540,1350,500,1490,980,1060,1060,
510,1270,1080,990,1470,1010,880,960,980,950,1400,
1510,1040,620,1190,1250,1290,1720,1120,810,1850,
700,860,990,1170,1470,1260,860,1060,930,1850,
1250,880,1450,620,1200,1020,1210,1250,840,1350,
1220,1190,910,860,820,1060,1160,1150,1310,1080,
840,780,1230,1120,1180,660,600,720,1260,820,890,
1250,700,1490,1270,1600,1070,1000,1270,740,1830,
1300,1270,1350,1020,1370,720,790,920,530,1610,
1080,540,650,1290,880,970,1060,910,1390,1120,880,
1360,1150,1540,1140,910,1180,1180)
ID <- 1:20
BfrCP <- c(3,5,5,3,2,5,3,1,3,2,3,4,2,1,3,3,4,2,2,4)
AftrCP <- c(2,4,3,4,3,5,4,5,2,4,2,5,3,3,5,5,3,5,5,4)
Intention <- data.frame(ID,BfrCP,AftrCP)
※こちらをコピーし、スクリプト画面に貼り付け、実行してください。
今月と前年同月の平均客単価の差
はじめに今月の平均客単価と前年同月の平均客単価に偶然でない差があるのかどうかを検定してみたいと思います。まずは帰無仮説と対立仮説を立てましょう。
- 帰無仮説:今月の平均客単価と前年同月の平均客単価に差はない
- 対立仮説:今月の平均客単価と前年同月の平均客単価に偶然でない差がある
この仮説検定をt検定で行いたいと思います。t検定はt.test()関数を使います。t.test()関数は引数に検定したい2つのベクトルデータを指定します。今回はThisMonthとLYMonthを比較するので、これらの変数をコンマで並べてt.test()関数の引数とします。
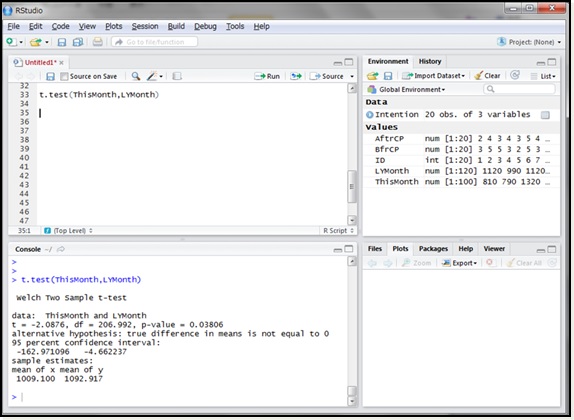
結果の見方を説明します。基本的にはp-valueさえ見ればOKです。
- p-value:今月と前年同月の平均客単価の差が、偶然によるものである確率で、p値のこと。
今回の結果ではp値が0.03717(≒3.7%)でした。有意水準を5%とすると、帰無仮説を棄却することになります。つまり、今月と前年同月の平均客単価には、偶然によらないほどの差があるということが言えます。
今月と前年1年間の平均客単価の差
前年同月との比較ではなく、前年1年間全体での平均客単価との比較を行いたいと思います。しかし、前年1年間の客単価は個別のデータがなく、平均客単価の値だけ分かっています。このようなときにも、t検定が使えます。
仮に、前年1年間の平均客単価が1,050円だったとします。この1,050円と今月の平均客単価の間に差があるのかをRで検定してみたいと思います。帰無仮説は「今月の平均客単価と前年1年間の平均客単価に差はない」ですね。
t.test()関数は、今回のように、全体の平均と個別のデータの平均との差を検定することができます。その方法は、t.test()関数の引数に比較したいデータおよび、mu=<全体の平均>と指定するだけです。
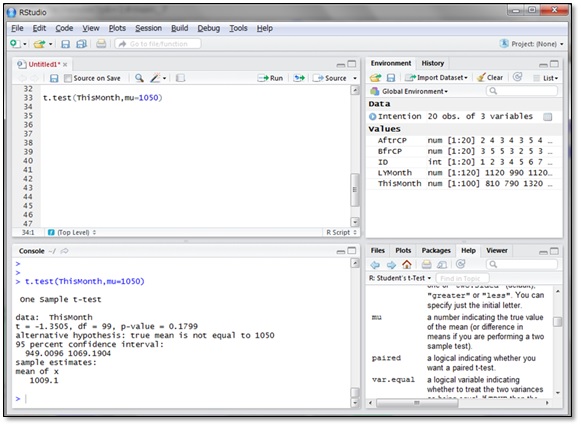
今月と前年全体との比較ではp値が0.1799(≒18%)であり、5%の有意水準では帰無仮説を棄却できません。つまり、差が偶然である確率が18%であるということです。
帰無仮説が棄却されなかった場合は、帰無仮説を受容します。つまり、「両者に差はない」ということですが、ここには特に気を付けなければならないポイントがあります。
帰無仮説が棄却できなかった場合、「このデータとこの検定方法では、積極的に差があるとは言えない」くらいの意味しかありません。より多くのデータを用い、より適切な検定方法を用いれば、帰無仮説が棄却される、つまり偶然でない差があるということも十分に考えられます。
キャンペーン施策前後の顧客の購入意欲の変化
t検定の3つ目は、対応のあるt検定と呼ばれるものです。何らかの施策を打ったときに、変化をもたらしたかどうかを知りたいといったときに使用する検定方法です。これは言い換えると、施策前後の値の差の平均が、0かそうでないかを検定します。
ここでは、キャンペーン施策前後の顧客の購入意欲がどのように変化したかを調べたいと思います。
平均客単価の検定との違いは、データの”でどころ”がデータ数と一致しているかしていないかの違いです。平均客単価のデータは、100人の顧客から今月のデータが100件取得され、120人の同じとは限らない顧客から前年同月のデータが120件取得されています。
一方キャンペーン施策のデータは、20人の顧客からキャンペーン前に20件、キャンペーン後に20件のデータが取得されており、同じ顧客が2つのデータを出しています。
このようなキャンペーン施策前後の変化の差についてのt検定をRで行うには、t.test()関数の引数に施策後のデータ、施策前のデータ、そして
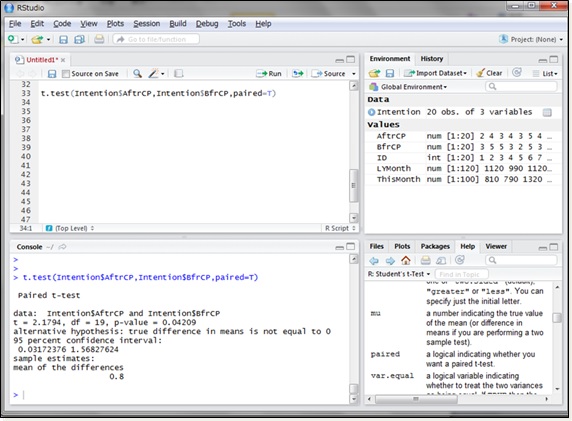
同様にp値を見てみると、0.04209(≒4.2%)となり、5%の有意水準では帰無仮説を棄却します。つまり、キャンペーン施策前後で顧客の購入意欲に何らかの変化が生じたと考えられます。
しかし、購入意欲が高まる方への変化なのか、弱まる方への変化なのかまでは明記されていません。それを判断するには最後の行の数字を見ます。この数字は最初の引数の平均から2番目の引数の平均を引いたものを表しています。この値がプラスであるため、購入意欲が高まる方への変化ということが分かります。
t検定は以上となります。
χ(カイ)二乗検定のやり方
前回のおさらい
χ二乗検定は、クロス集計の結果に対して全体の割合に差があるかどうかを検定するものです。たとえば、店舗Aと店舗Bの来客者の性別ごとの人数を集計した時に、次の結果になったとします。
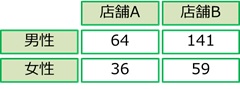
店舗AとBで男女の割合に差があるかどうかを検定するのがχ二乗検定になります。帰無仮説は、「店舗AとBで男女の割合に差はない」です。
χ二乗検定の実行
χ二乗検定を行うRの関数は、chisq.test()関数です。引数には集計結果となる上図のような行列を指定します。まずはこのような行列を作成した上で、χ二乗検定を実行してみましょう。
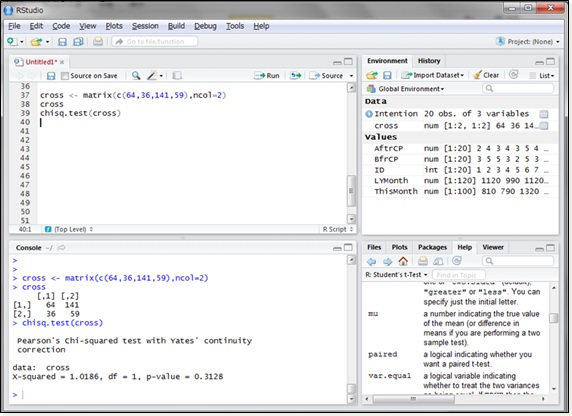
まずcrossという変数に行列を作成しています。行列を作成する関数はmatrix()関数です。引数にベクトルと、列数のncolを指定します。行列ができるときには縦の1列目から順に数字が配置されますので、ベクトルの数値の順番には気を付けてください。
crossを見てみると、横2行、縦2列の行列ができています。この行列をそのままchisq.test()関数の引数にすることで、χ二乗検定を行うことができます。
χ二乗検定でもt検定でも同様にp値が計算されます。今回は0.3138(≒31%)であり帰無仮説を棄却できません。すなわち、店舗AとBでは来店客の男女比に違いは見出せませんでした。
さて、実際のデータは集計された状態ではありません。次のようにデータフレームのような形でデータは存在しています。
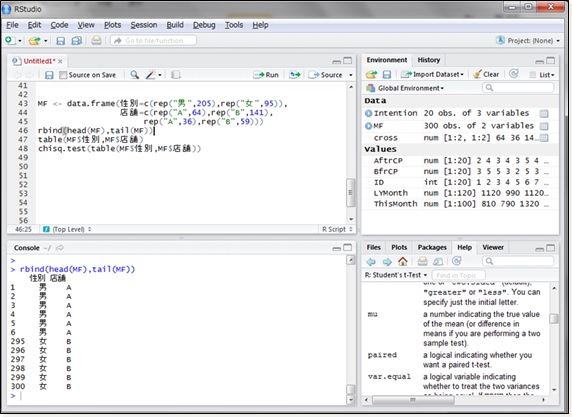
データフレームから集計を行うには、table()関数を使います。集計したい列を引数に指定することで、行列の形で集計できます。また、chisq.test()関数は、table()関数で集計した結果も引数に指定できます。
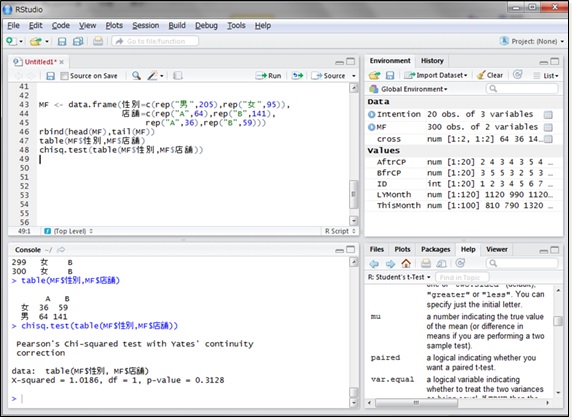
【コピー&ペースト用データ】
MF <- data.frame(性別=c(rep(“男”,205),rep(“女”,95)),
店舗=c(rep(“A”,64),rep(“B”,141),
rep(“A”,36),rep(“B”,59)))
rbind(head(MF),tail(MF))
table(MF$性別,MF$店舗)
chisq.test(table(MF$性別,MF$店舗))
χ二乗検定は、男女や店舗名などの数値以外のデータに対し、その個数を用いて検定を行う方法です。数値データの平均に関する検定はt検定、数値でないデータの集計結果に関する検定はχ二乗検定と覚えておくと良いでしょう。
さて、仮説検定のお話はここまで。2回に分けてお送りしましたが、少し統計っぽい内容となりました。
実際にRを動かしてひとつずつ進めて行ってくださいね。
アサインナビでは、データサイエンスに関するセミナーを随時開催しております。
過去には、データサイエンティストの知識を習得するための実践塾や、特別講師を招いてのセミナーなどを開催しております。
過去の様子はこちらからご確認いただけます。
▼データサイエンティスト実践塾▼
第1回データサイエンティスト実践塾を修了しました!
▼データサイエンスの現状と未来▼
シリコンバレーに学ぶ、日本のデータサイエンスの現状と未来 ~これからのデータドリブンな時代に本当に必要なこと~を開催しました





